👦 내일배움캠프/TIL(Today I Learned)
TIL_220516_머신러닝 프로젝트 기초
- -
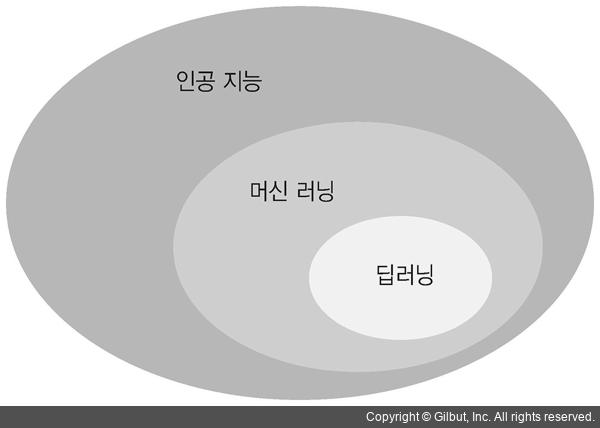
딥 러닝이란?
딥 러닝 :
- 머신 러닝의 한 분야
- 층(Layer)을 깊게(Deep) 쌓는다고 해서 딥러닝
- 딥러닝의 다른 단어 표현
- 딥러닝(Deep learning)
- Deep neural networks
- Multilayer Perceptron(MLP)
- 딥러닝의 주요 개념과 기법
- 배치 사이즈와 에폭
- 활성화 함수
- 과적합과 과소적합
- 데이터 증강
- 드랍아웃
- 앙상블
- 학습률 조정
딥러닝의 역사
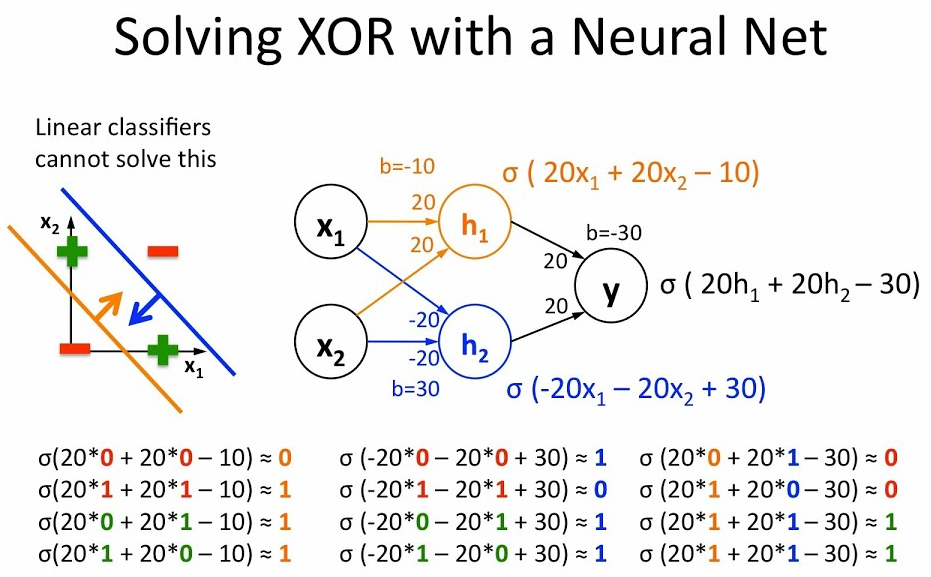
XOR 문제 :
기존의 머신러닝은 AND, OR 문제로부터 시작
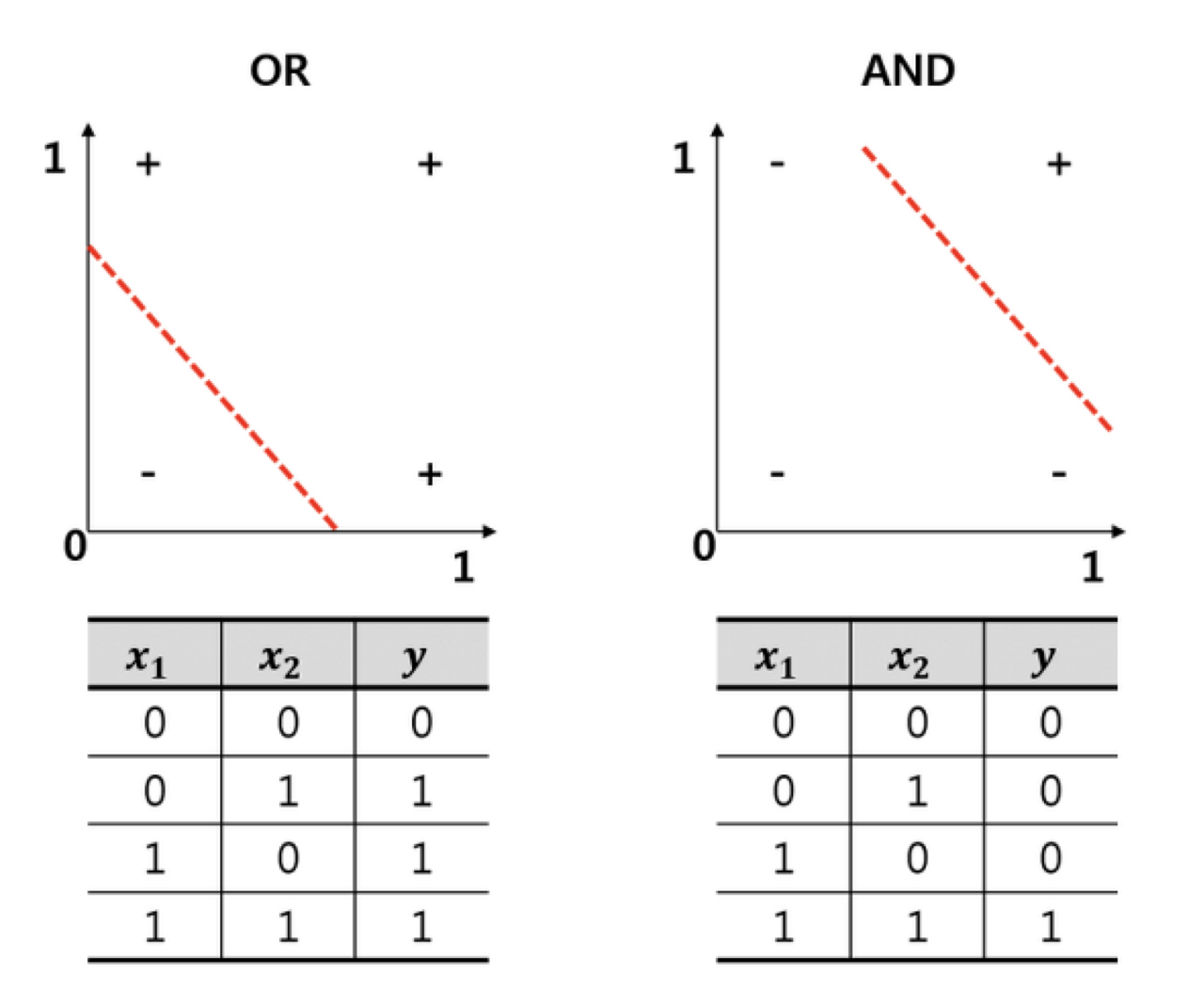
Perceptron(퍼셉트론) :

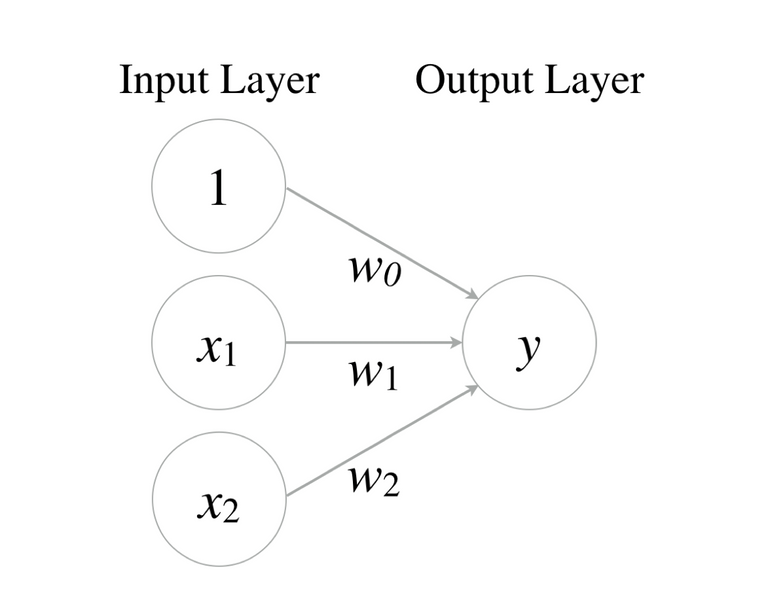
하지만 학습 시키기에는 XOR문제를 풀지 못했다.
Multilayer Perceptrons (MLP)라는 개념을 통해 문제를 풀어보려고 했으나 실패.

Backpropagation (역전파) :
1974년에 발표된 Paul Werbos(폴)이라는 사람의 박사 논문의 시작
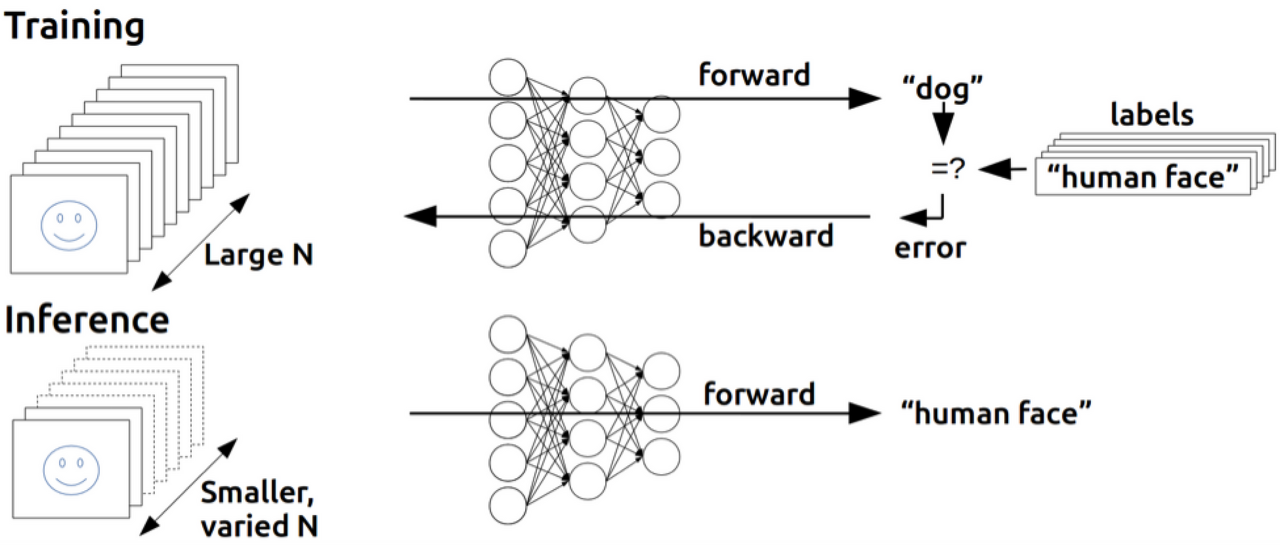
- 우리는 W(weight)와 b(bias)를 이용해서 주어진 입력을 가지고 출력을 만들어 낼 수 있다.
- 그런데 MLP가 만들어낸 출력이 정답값과 다를 경우 W와 b를 조절해야한다.
- 그것을 조절하는 가장 좋은 방법은 출력에서 Error(오차)를 발견하여 뒤에서 앞으로 점차 조절하는 방법이 필요하다.
' 1986년에 Hinton 교수가 똑같은 방법을 독자적으로 발표 : 핵심방법은 바로 역전파 알고리즘의 발견 '
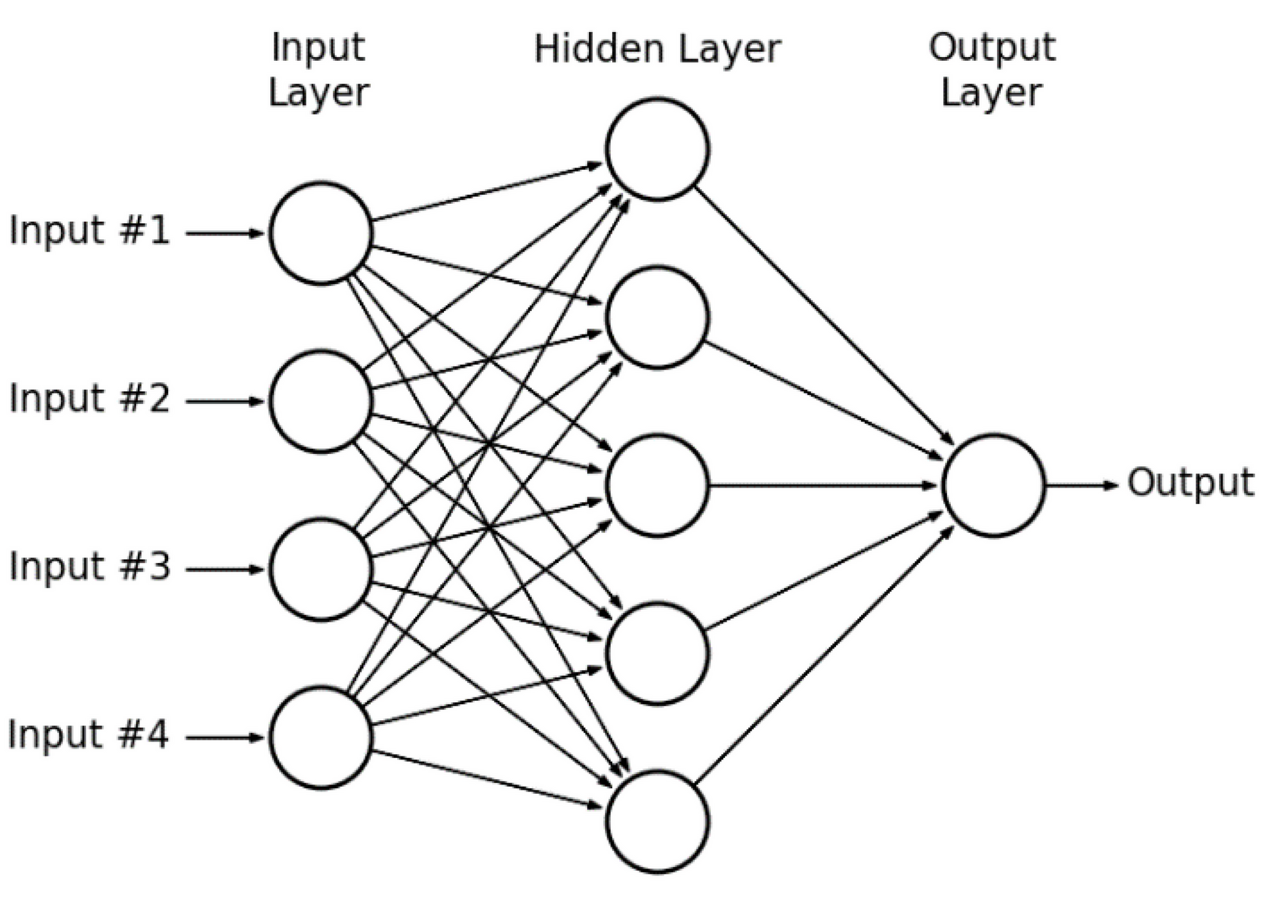
Deep Neural Networks 구성 방법
Layer(층) 쌓기 :
- Input layer(입력층): 네트워크의 입력 부분입니다. 우리가 학습시키고 싶은 x 값입니다.
- Output layer(출력층): 네트워크의 출력 부분입니다. 우리가 예측한 값, 즉 y 값입니다.
- Hidden layers(은닉층): 입력층과 출력층을 제외한 중간층입니다.
- 풀어야할 문제에 따른 입력층과 출력층의 모양이 정해짐.
- 대표적으로 신경써야할 층은 은닉층 : 완전연결 계층 (Fully connected layer = Dense layer)

기본적인 뉴럴 네트워크(Deep neural networks) 구성 :
- 입력층의 노드 개수 4개
- 첫 번째 은닉층 노드 개수 8개
- 두 번째 은닉층 노드 개수 16개
- 세 번째 은닉층 노드개수 8개
- 출력층 노드개수 3개
- 활성화 함수(activation function)를 보편적인 경우 모든 은닉층 바로 뒤에 위치

네트워크의 Width(너비)와 Depth(깊이) 개념
Baseline model(베이스라인 모델) : 적당한 정확도의 딥러닝 모델
- 입력층: 4
- 첫 번째 은닉층: 8
- 두 번째 은닉층: 4
- 출력층: 1
기본적인 실험(튜닝)의 예시
1) 네트워크의 너비를 늘리는 방법
- 입력층: 4
- 첫 번째 은닉층: 8 * 2 = 16
- 두 번째 은닉층: 4 * 2 = 8
- 출력층: 1
2) 네트워크의 깊이를 늘리는 방법
- 입력층: 4
- 첫 번째 은닉층: 4
- 두 번째 은닉층: 8
- 세 번째 은닉층: 8
- 네 번째 은닉층: 4
- 출력층: 1
3) 너비와 깊이를 전부 늘리는 방법
- 입력층: 4
- 첫 번째 은닉층: 8
- 두 번째 은닉층: 16
- 세 번째 은닉층: 16
- 네 번째 은닉층: 8
- 출력층: 1
실무에서는 네트워크의 너비와 깊이를 바꾸면서 실험을 많이 함. 그만큼 시간도 많이 들고 지루한 작업. 과적합과 과소적합을 피하기위해서는 꼭 필요한 노가다이다.
딥러닝의 주요 개념
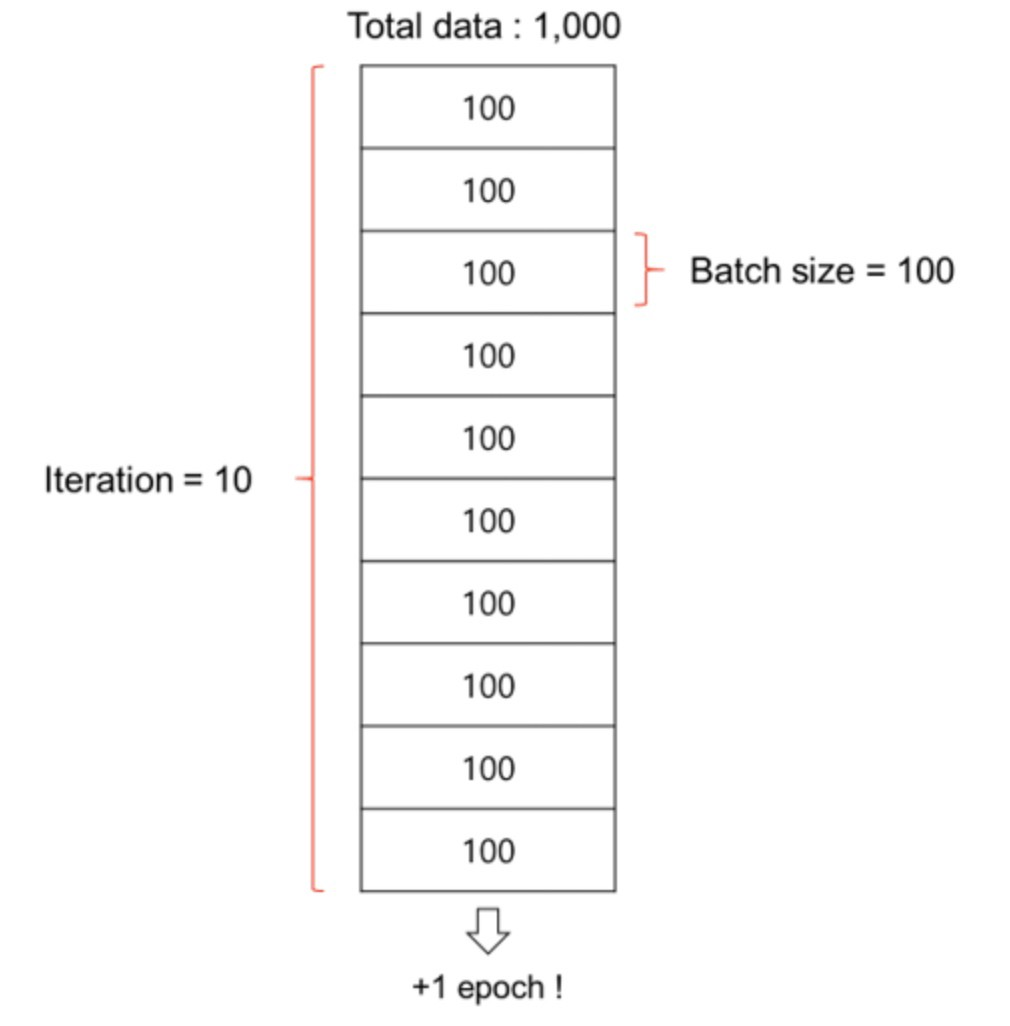
Batch size, Epoch (배치 사이즈, 에폭)
batch와 iteration
- 데이터셋을 작은 단위로 쪼개서 학습을 시키는데 쪼개는 단위를 배치(Batch)
- 쪼개는 과정을 반복하는 것을 Iteration(이터레이션)
epoch
- 문제를 여러번 풀어보는 과정 epochs(에폭)
- batch를 몇 개로 나눠놓았냐에 상관 없이 전체 데이터셋을 한 번 돌 때 한 epoch이 끝남.
따라서 1천만개의 데이터셋을 1천개 단위의 배치로 쪼개면, 1만개의 배치가 되고, 이 1만개의 배치를 100에폭을 돈다고 하면 1만 * 100 = 100만번의 이터레이션을 도는 것이 됩니다!
Activation functions (활성화 함수)
- 활성화 함수는 비선형 함수 : 시그모이드 함수
연구자들은 뉴런의 신호전달 체계를 흉내내는 함수를 수학적으로 만들었는데, 전기 신호의 임계치를 넘어야 다음 뉴런이 활성화 한다고해서 활성화 함수라고 부른다.
- 대표적인 예 : 시그모이드 함수

- 활성화 함수의 여러가지 종류
- 딥러닝에서 가장 많이 보편적으로 쓰이는 활성화함수는 단연 ReLU(렐루)
- 다른 활성화 함수에 비해 학습이 빠르고, 연산 비용이 적고, 구현이 간단

Overfitting, Underfitting (과적합, 과소적합)
과적합 현상(Overfitting)
- Training loss는 점점 낮아지는데 Validation loss가 높아지는 시점
- 문제의 난이도에 비해 모델의 복잡도(Complexity)가 클 경우 가장 많이 발생하는 현상
과소적합(Underfitting)
- 반대로 우리가 풀어야하는 문제의 난이도에 비해 모델의 복잡도가 낮을 경우 문제를 제대로 풀지 못하는 현상
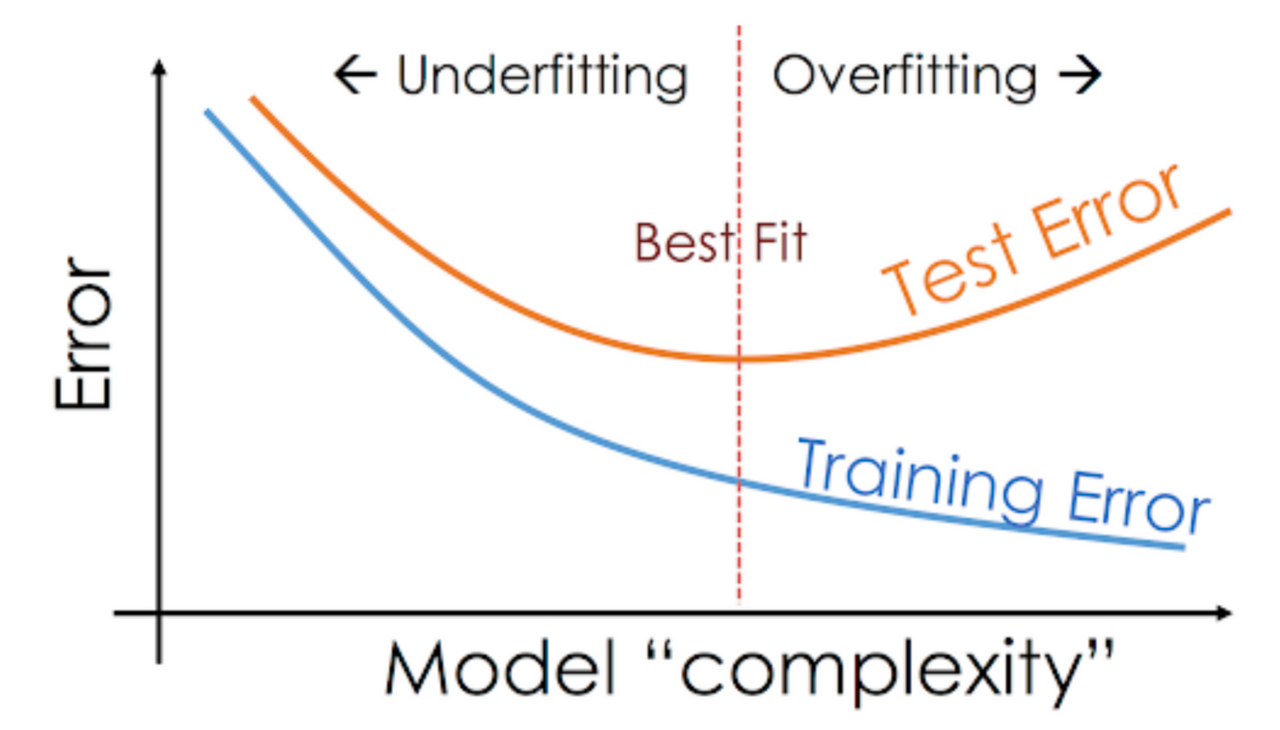
우리는 적당한 복잡도를 가진 모델을 찾아야 하고 수십번의 튜닝 과정을 거쳐 최적합(Best fit)의 모델을 찾아야한다.
과적합(Overfitting)을 해결하는 방법에는 여러가지 방법이 있지만 대표적인 방법으로는 데이터를 더 모으기, Data augmenation, Dropout 등이 있다.
딥러닝의 주요 스킬
Data augmentation (데이터 증강기법)
- 과적합을 해결할 가장 좋은 방법은 데이터의 개수를 늘리는 방법
- 부족한 데이터를 보충하기위해 우리는 데이터 증강기법이라는 꼼수아닌 꼼수를 사용
- 이미지 처리 분야의 딥러닝에서 주로 사용하는 기법

Dropout (드랍아웃)
- 과적합을 해결할 수 있는 가장 간단한 방법
- 각 노드들이 이어진 선을 빼서 없애버린다는 의미
- 각 배치마다 랜덤한 노드를 끊어버림. 즉 다음 노드로 전달할 때 랜덤하게 출력을 0으로 만들어버리는 것과 같다.


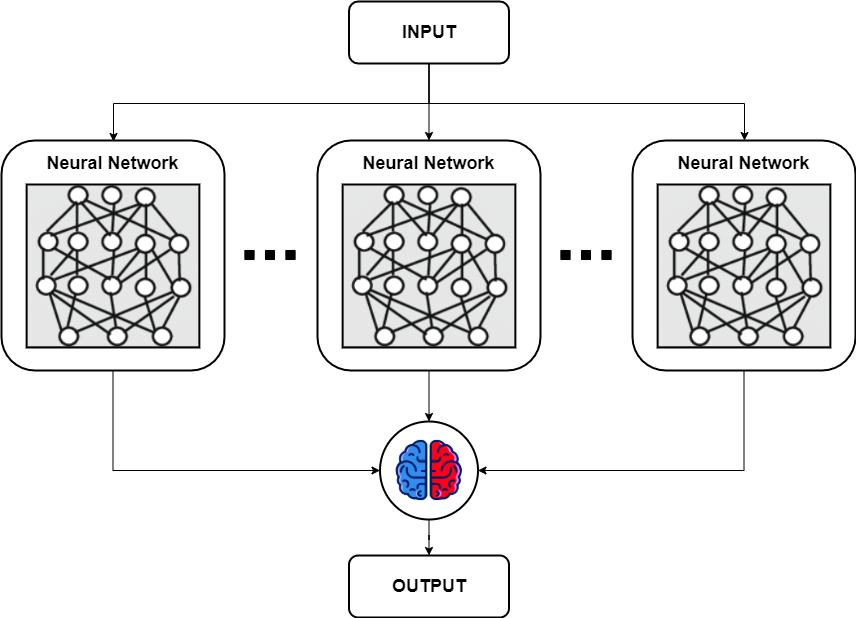
Ensemble (앙상블)
- 컴퓨팅 파워만 충분하다면 가장 시도해보기 쉬운 방법
- 여러개의 딥러닝 모델을 만들어 각각 학습시킨 후 각각의 모델에서 나온 출력을 기반으로 투표를 하는 방법
- 랜덤 포레스트의 기법과 비슷
- 여러개의 모델에서 나온 출력에서 다수결로 투표(Majority voting)를 하는 방법도 있고, 평균값을 구하는 방법도 있고, 마지막에 결정하는 레이어를 붙이는 경우 등 다양한 방법으로 응용이 가능
- 앙상블을 사용할 경우 최소 2% 이상의 성능 향상 효과를 볼 수 있다
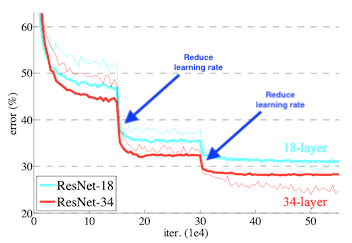
Learning rate decay (Learning rate schedules)
- 실무에서도 자주 쓰는 기법
- Local minimum에 빠르게 도달하고 싶을 때 사용
- 왼쪽(Decaying) : (선호) 큰 폭으로 건너뛰고 뒷부분으로 갈 수록 점점 조금씩 움직여서 효율적으로 Local minimum을 찾는 모습
- 오른쪽(Decent) : Learning rate를 고정시켰을 때의 모습
- Keras 에서 자주 사용 : tf.keras.callbacks.LearningRateScheduler() 와 tf.keras.callbacks.ReduceLROnPlateau() 로 Learning rate를 조절

3주차 숙제
'머신러닝에서 가장 유명한 데이터셋 중 하나인 MNIST 데이터베이스를 직접 분석해보도록 합시다!'
MNIST 데이터베이스는 손으로 쓴 0 ~ 9 까지의 숫자 이미지 모음이라고 한다.
숙제이니.. 분석해보도록 하자.
기본 틀
더보기
# 데이터셋 다운로드
!kaggle datasets download -d oddrationale/mnist-in-csv
!unzip mnist-in-csv.zip
# 패키지 로드
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense
from tensorflow.keras.optimizers import Adam, SGD
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import OneHotEncoder
# 데이터셋 로드
train_df = pd.read_csv('mnist_train.csv')
train_df.head()
test_df = pd.read_csv('mnist_test.csv')
test_df.head()
# 라벨 분포
sns.countplot(train_df['label'])
plt.show()
# 전처리
train_df = train_df.astype(np.float32)
# 소수점 float32 (비트) 로 바꿈.
x_train = train_df.drop(columns=['label'], axis=1).values
# x 값에는 label 만 빼주고, (().values) 는 데이터프레임에서 np.array 로 변환
y_train = train_df[['label']].values
# y 값에는 label 만 넣어줌.
test_df = test_df.astype(np.float32)
x_test = test_df.drop(columns=['label'], axis=1).values
y_test = test_df[['label']].values
print(x_train.shape, y_train.shape)
# 트레이닝 : 데이터셋은 27455, 입력 노드의 개수 픽셀의 크기 : 784 / output 의 노드의 개수 1개
print(x_test.shape, y_test.shape)
# 테스트 : 데이터셋은 7172, 입력 노드의 개수 픽셀의 크기 : 784 / output 의 노드의 개수 1개
# 데이터 미리보기
index = 1
plt.title(str(y_train[index]))
plt.imshow(x_train[index].reshape((28, 28)), cmap='gray')
# reshape 으로 이차원으로 변환 (x:28px, y:28px), cmap='gray' 그레이스케일 변환
plt.show()
# 6=G번에 해당하는 (28, 28) 이미지
# 정상적으로 변환이 되었는지 확인 방법 : One-hot encoding 후 데이터 미리보기 재실행
# One-hot encoding
encoder = OneHotEncoder()
y_train = encoder.fit_transform(y_train).toarray()
# 라벨 값만 One-hot encoding 적용 후 array 형태로 변환
y_test = encoder.fit_transform(y_test).toarray()
print(y_train.shape)
# 정상적으로 변환이 되었는지 확인 방법 : One-hot encoding 후 데이터 미리보기 재실행
# 일반화
x_train = x_train / 255. # 0 ~ 255 의 데이터를 255 로 나누면 0 과 1 데이터로 구분
# 이미지 데이터의 최대 픽셀은 255px
x_test = x_test / 255.
# 1번 이상 실행시켰을 경우 2번의 나눔 값이 적용되기 때문에 꼭 1번만 실행할 것.
# 네트워크 구성
input = Input(shape=(784,))
hidden = Dense(1024, activation='relu')(input)
hidden = Dense(512, activation='relu')(hidden)
hidden = Dense(256, activation='relu')(hidden)
output = Dense(10, activation='softmax')(hidden)
# output, Dense 원하는 값의 종류 수 0~9개 10개
# shape 로 Dense 값 확인
# activation='softmax' : 다항 논리 회귀 사용
model = Model(inputs=input, outputs=output)
model.compile(loss='categorical_crossentropy',= optimizer=Adam(lr=0.001), metrics['acc'])
# 다항 논리 회귀 : categorical_crossentropy 사용
# metrics=['acc'] : 0 ~ 1 사이로 정확도를 퍼센트로 나타냄
model.summary()
# 학습
history = model.fit(
x_train,
y_train,
validation_data=(x_test, y_test), # 검증 데이터를 넣어주면 한 epoch이 끝날때마다 자동으로 검증
epochs=20 # epochs 복수형으로 쓰기!
)
# 학습 결과 그래프
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
# .plot 로 그래프 그리기
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
에러 노트
이전 실습과 동일한 폼으로 안에 들어갈 내용을 수정하고 실행했다.
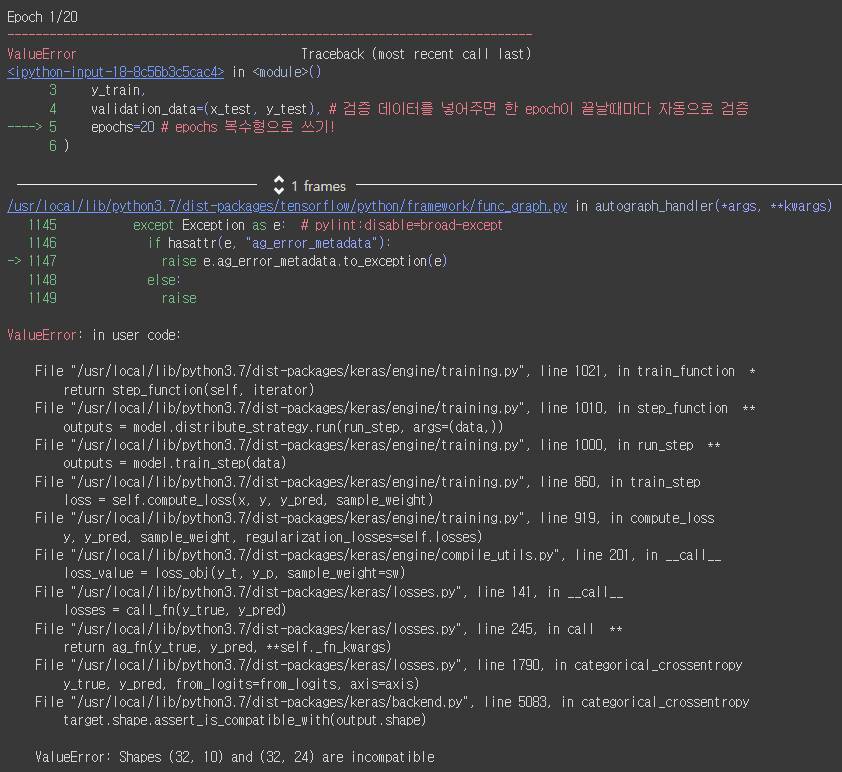
쉽게 넘어갈 친구가 아니지 ^^..
처음엔 원인이 뭔지를 상단에서 에러가 되는 문구를 구글링하며 찾아봤지만,
답이 좀처럼 보이지 않았다.
그러다
같은 팀원에게 물어봤는데,
아니 왠걸 팀원은 가장 밑에 에러에 대한 부분을 가리키며 'Shapes' 에 대한 오류라고 알려주었다.
이렇게만 봐선 Shapes 의 뭐가 잘못된건지 몰랐는데,

꼭 이런 친구들 있지 않은가..
출제된 문제를 읽고 해당하는 값을 구하시오.
분명 0 ~ 9 까지의 값을 찾으라 했거늘
10(0~9)이 아닌 24 라는 값을 넣고 출력이 잘 나와주길 바라는 나 자신.. 유죄..
바로 10 으로 고쳐쓰고 재실행 했더니 너무 잘 되었다..

출처 스파르타코딩클럽
'👦 내일배움캠프 > TIL(Today I Learned)' 카테고리의 다른 글
| TIL_220518_팀 프로젝트_머신러닝 (0) | 2023.01.01 |
|---|---|
| TIL_220517_머신러닝 프로젝트 기초 (0) | 2023.01.01 |
| TIL_220513_머신러닝 프로젝트 기초 (0) | 2023.01.01 |
| TIL_220512_머신러닝 프로젝트 기초 (0) | 2023.01.01 |
| TIL_220511_팀 프로젝트 종료_KPT (0) | 2023.01.01 |
Contents
소중한 공감 감사합니다