👦 내일배움캠프/TIL(Today I Learned)
TIL_220512_머신러닝 프로젝트 기초
- -
어제부로 팀 프로젝트가 끝나고,
드디어 시작한 머신러닝 교육과정!!
(가슴이 웅장해진다..!!!)
근데.. 캠퍼들 분위기가 왜 그러지..??!!
(어리둥절)
알고 봤더니 이번 머신 러닝에는 수학적인 능력이 상당히 필요하다 하더라..

아니.. 시작도 안해보고 기가 죽어서야 되겠어?!!
일단 시작해본다..
맛이라도 보고 판단하고 생각해보자.
내가 이 맛을 감당할 수 있는지를!!!
오늘의 목표 : 머신러닝 1주차 과정 완강하기
선형회귀 :
- 컴퓨터가 풀 수 있는 문제 중에 가장 간단한 것이 바로 두 데이터 간의 직선 관계를 찾아 내서 x값이 주어졌을 때 y값을 예측
강의를 진행하시는 튜터님의 권장사항
영어 권장
- 구글, Stackoverflow 등의 사이트에서 영어를 많이 씀
- 의사소통시 영어로 소통해야 의사소통 오류가 적음
- 외국인 엔지니어와의 의사소통
- 외국계 기업 취업
- 심하게 아는 척 가능
구글링
- 실무에서 실제로 구글링이 차지하는 비율이 90% 이상
- 검색 능력이 곧 업무 성과에 비례하는 경우가 많음
- 새로운 분야를 개척할 수록 질문할 사람(사수)이 없는 경우가 많음
알고리즘
- 수학과 컴퓨터 과학, 언어학 또는 관련 분야에서 어떠한 문제를 해결하기 위해 정해진 일련의 절차나 방법을 공식화한 형태로 표현
- 계산을 실행하기 위한 단계적 절차
- 위키피디아
회귀(Regression) : 출력값이 연속적인 소수점으로 예측하게 하도록 푸는 방법
분류(Classification) : 입력값에 따른 출력값 여부(Pass or fail)를 예측
머신러닝의 분류
지도 학습 (Supervised learning) : 정답을 알려주면서 학습시키는 방법
비지도 학습 (Unsupervised learning) : 정답을 알려주지 않고 군집화(Clustering)하는 방법
강화 학습 (Reinforcement learning) : 주어진 데이터없이 실행과 오류를 반복하면서 학습하는 방법 (알파고를 탄생시킨 머신러닝 방법!!)
선형 회귀와 가설, 손실함수
- 가설 : H(x) = Wx + b / W : weight * x / b : bias / (직선 = 1차 함수)
- 정확한 시험 점수를 예측하기 위해 임의의 직선(가설)과 점(정답)의 거리가 가까워지도록
- 손실함수 : Cost = {{1\over N}\sum_{i=1}^{N}{(H(x_i) - y_i) ^ 2}}
- 우리가 임의로 만든 직선 H(x)를 가설(Hypothesis)이라고 하고 Cost를 손실 함수(Cost or Loss function)라고 합니다.
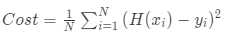
다중 선형 회귀
- 가설 $H(x_1, x_2, ..., x_n) = w_1x_1 + w_2x_2 + ... + w_nx_n + b$
- 손실 함수 $Cost = {{1\over N}\sum{(H(x_1, x_2, x_3, ..., x_n) - y) ^ 2}}$
중요!!) 경사 하강법 (Gradient descent method)
경사 하강법
- 1차 근삿값 발견용 최적화 알고리즘
- 함수의 기울기(경사)를 구하고 경사의 절댓값이 낮은 쪽으로 계속 이동시켜 극값에 이를 때까지 반복
- Learning rate : 한칸씩 전진하는 단위
- 적당한 Learning rate를 찾는 노가다가 필수
- Overshooting : 찾으려는 최소값을 지나치고 검은 점은 계속 진동하다가 최악의 경우에는 발산
머신러닝 엔지니어의 핵심 역할
- 손실 함수의 최소점인 Global cost minimum을 찾는 것
- Global minimum을 찾기 위해 좋은 가설과 좋은 손실 함수를 만들어서 기계가 잘 학습할 수 있도록 설정
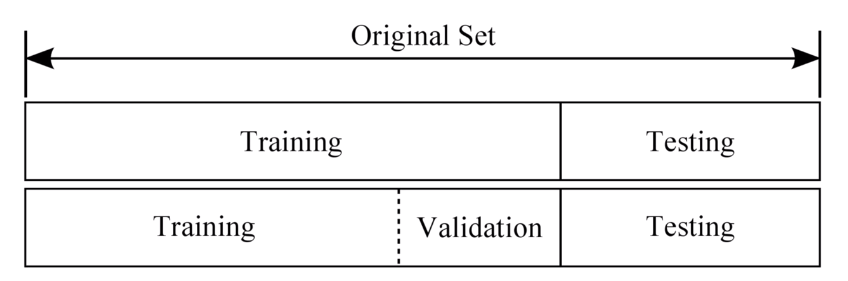
Training set (학습 데이터셋, 트레이닝셋) = 교과서
- 머신러닝 모델을 학습시키는 용도로 사용.
- 전체 데이터셋의 약 80% 정도를 차지
Validation set (검증 데이터셋, 밸리데이션셋) = 모의고사
- 머신 러닝 모델의 성능을 검증, 튜닝하는 지표의 용도로 사용
- 모델의 성능에 영향을 미치지 않음
- 손실함수, Optimizer 등을 바꾸면서 모델을 검증하는 용도
- 전체 데이터셋의 약 20% 정도 차지
Test set (평가 데이터셋, 테스트셋) = 수능
- 실제 환경에서의 평가 데이터셋
- 실무 적용 시 : Training set > Validation set > Test set 순으로 꼭 이행
1주차 숙제
연차로부터 연봉을 예측해보아요~
이번 강의 내용 중에 가장 많이 듣게 되었던 말..
"정말 쉽죠?"
(ㄹㅇ 거짓말 아니고..)
내용부터가 뭔가 전공자 혹은 그 이상의 수준에 미치는 사람들을 대상으로 짜여있는 수준인듯 했다.
그래도 뭐.. 해봐야지
노가다는 전문이지..!
실습
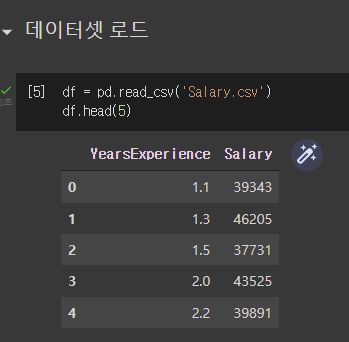
1) 가장 먼저 데이터 로드
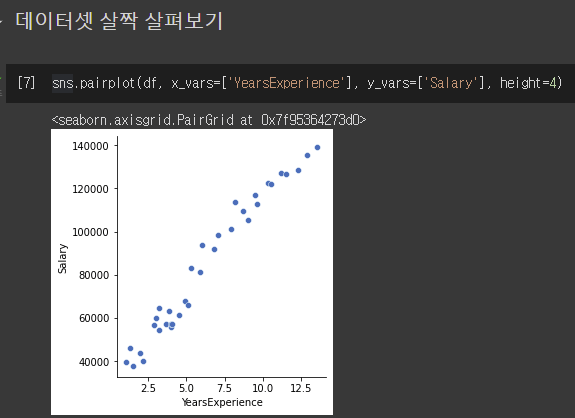
2) 데이터셋 살피기
3) 2가지 방향성에 대한 실습
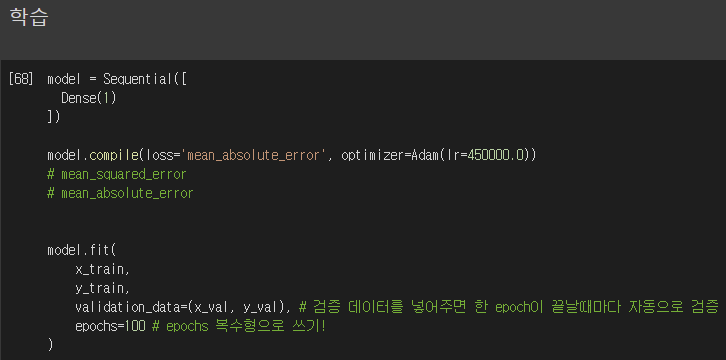
3-1 : loss='mean_squared_error' optimizer=Adam(lr=450000.0)
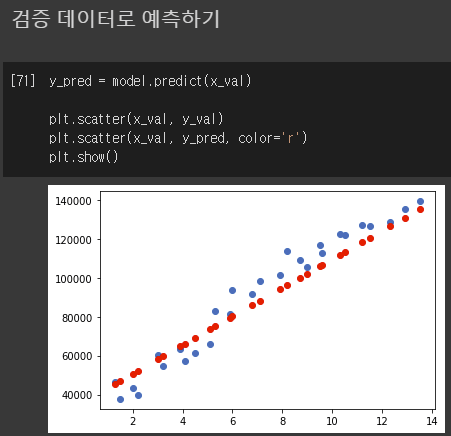
3-2 : loss='mean_absolute_error' optimizer=Adam(lr=450000.0)

3-3 : loss='mean_absolute_error' optimizer=Adam(lr=250000.0)

3-4 : loss='mean_absolute_error' optimizer=Adam(lr=400000.0)

답안코드
loss='mean_squared_error', optimizer=SGD(lr=0.01)
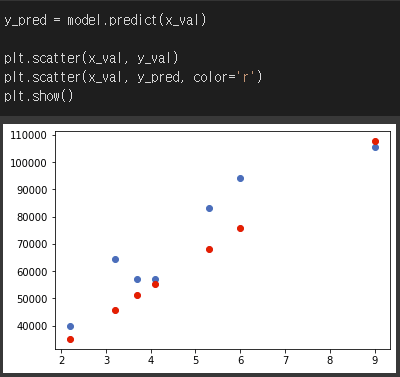
optimizer 은 왠만하면 Adam 으로 사용하라고 들었던 것 같은데,
어떤 Optimizer를 써야되는지 잘 모르겠다면 Adam을 써라
답은 다른 걸로 사용했네.. 하하
그래도 근접하게 찾았는데.. 잘한걸까..??
출처 스파르타코딩클럽
'👦 내일배움캠프 > TIL(Today I Learned)' 카테고리의 다른 글
| TIL_220516_머신러닝 프로젝트 기초 (0) | 2023.01.01 |
|---|---|
| TIL_220513_머신러닝 프로젝트 기초 (0) | 2023.01.01 |
| TIL_220511_팀 프로젝트 종료_KPT (0) | 2023.01.01 |
| TIL_220510_팀 프로젝트 (0) | 2023.01.01 |
| TIL_220509_팀 프로젝트 오류 노트 (0) | 2023.01.01 |
Contents
소중한 공감 감사합니다